---
language:
- en # English
- zh # Chinese
- es # Spanish
- pt # Portuguese
- de # German
- ja # Japanese
- ko # Korean
- fr # French
- ru # Russian
- id # Indonesian
- sv # Swedish
- it # Italian
- he # Hebrew
- nl # Dutch
- pl # Polish
- no # Norwegian
- tr # Turkish
- th # Thai
- ar # Arabic
- hu # Hungarian
- ca # Catalan
- cs # Czech
- da # Danish
- fa # Persian
- af # Afrikaans
- hi # Hindi
- fi # Finnish
- et # Estonian
- aa # Afar
- el # Greek
- ro # Romanian
- vi # Vietnamese
- bg # Bulgarian
- is # Icelandic
- sl # Slovenian
- sk # Slovak
- lt # Lithuanian
- sw # Swahili
- uk # Ukrainian
- kl # Kalaallisut
- lv # Latvian
- hr # Croatian
- ne # Nepali
- sr # Serbian
- tl # Filipino (ISO 639-1; 常见工程别名: fil)
- yi # Yiddish
- ms # Malay
- ur # Urdu
- mn # Mongolian
- hy # Armenian
- jv # Javanese
license: mit
pipeline_tag: automatic-speech-recognition
tags:
- ASR
- Transcriptoin
- Diarization
- Speech-to-Text
library_name: transformers
---
## VibeVoice-ASR
[](https://github.com/microsoft/VibeVoice)
[](https://aka.ms/vibevoice-asr)
[](https://arxiv.org/pdf/2601.18184)
**VibeVoice-ASR** is a unified speech-to-text model designed to handle **60-minute long-form audio** in a single pass, generating structured transcriptions containing **Who (Speaker), When (Timestamps), and What (Content)**, with support for **Customized Hotwords** and over **50 languages**.
➡️ **Code:** [microsoft/VibeVoice](https://github.com/microsoft/VibeVoice)
➡️ **Demo:** [VibeVoice-ASR-Demo](https://aka.ms/vibevoice-asr)
➡️ **Report:** [VibeVoice-ASR Technical Report](https://arxiv.org/pdf/2601.18184)
➡️ **Finetuning:** [Finetuning](https://github.com/microsoft/VibeVoice/blob/main/finetuning-asr/README.md)
➡️ **vLLM:** [vLLM-VibeVoice-ASR](https://github.com/microsoft/VibeVoice/blob/main/docs/vibevoice-vllm-asr.md)

## 🔥 Key Features
- **🕒 60-minute Single-Pass Processing**:
Unlike conventional ASR models that slice audio into short chunks (often losing global context), VibeVoice ASR accepts up to **60 minutes** of continuous audio input within 64K token length. This ensures consistent speaker tracking and semantic coherence across the entire hour.
- **👤 Customized Hotwords**:
Users can provide customized hotwords (e.g., specific names, technical terms, or background info) to guide the recognition process, significantly improving accuracy on domain-specific content.
- **📝 Rich Transcription (Who, When, What)**:
The model jointly performs ASR, diarization, and timestamping, producing a structured output that indicates *who* said *what* and *when*.
- **🌍 Multilingual & Code-Switching Support**:
It supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Language distribution can be found [here](#language-distribution).
## Evaluation


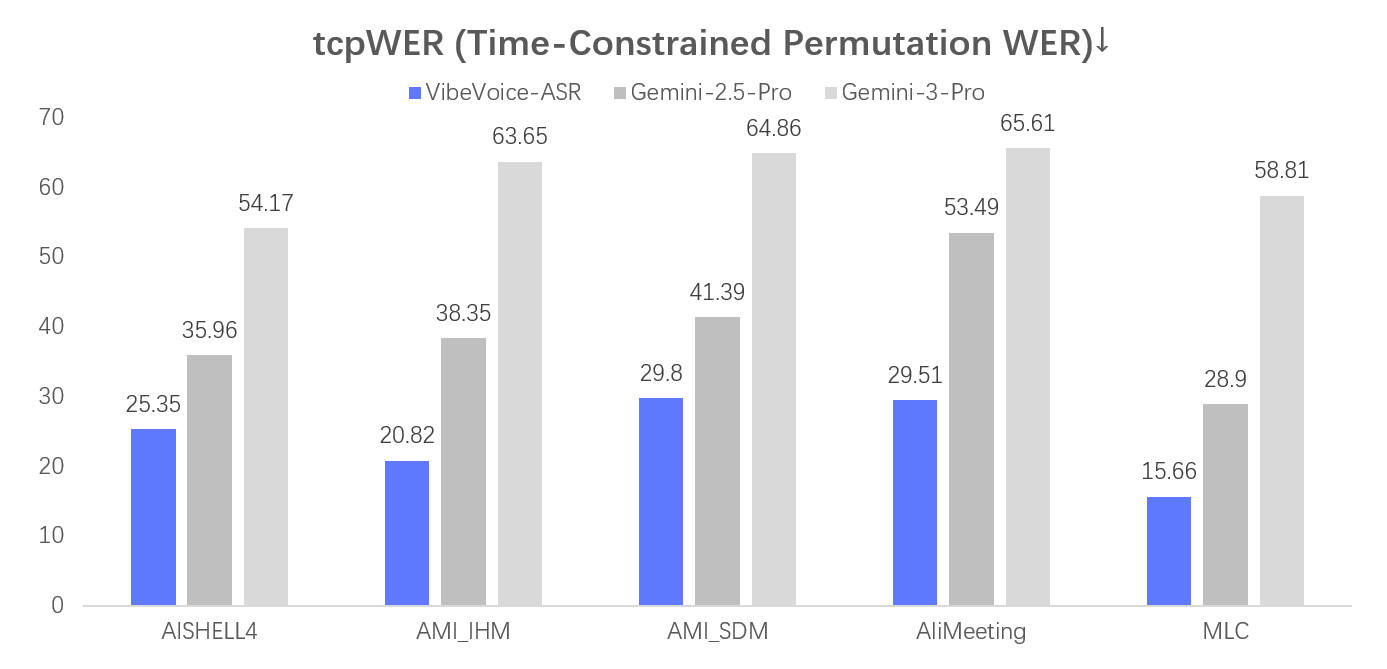
## Installation and Usage
Please refer to [GitHub README](https://github.com/microsoft/VibeVoice/blob/main/docs/vibevoice-asr.md#installation).
## Language Distribution

## License
This project is licensed under the MIT License.
## Contact
This project was conducted by members of Microsoft Research. We welcome feedback and collaboration from our audience. If you have suggestions, questions, or observe unexpected/offensive behavior in our technology, please contact us at VibeVoice@microsoft.com.
If the team receives reports of undesired behavior or identifies issues independently, we will update this repository with appropriate mitigations.